Chapter V
Conclusion
Addressing the overreliance of AI systems on addition, branching, and copying within deep learning systems, these chapters proposed three methods for addressing AI’s overreliance on addition, branching, and copying. However, none of the three solutions, taken alone, provides attribution-based control.
Three Problems and Three Solutions
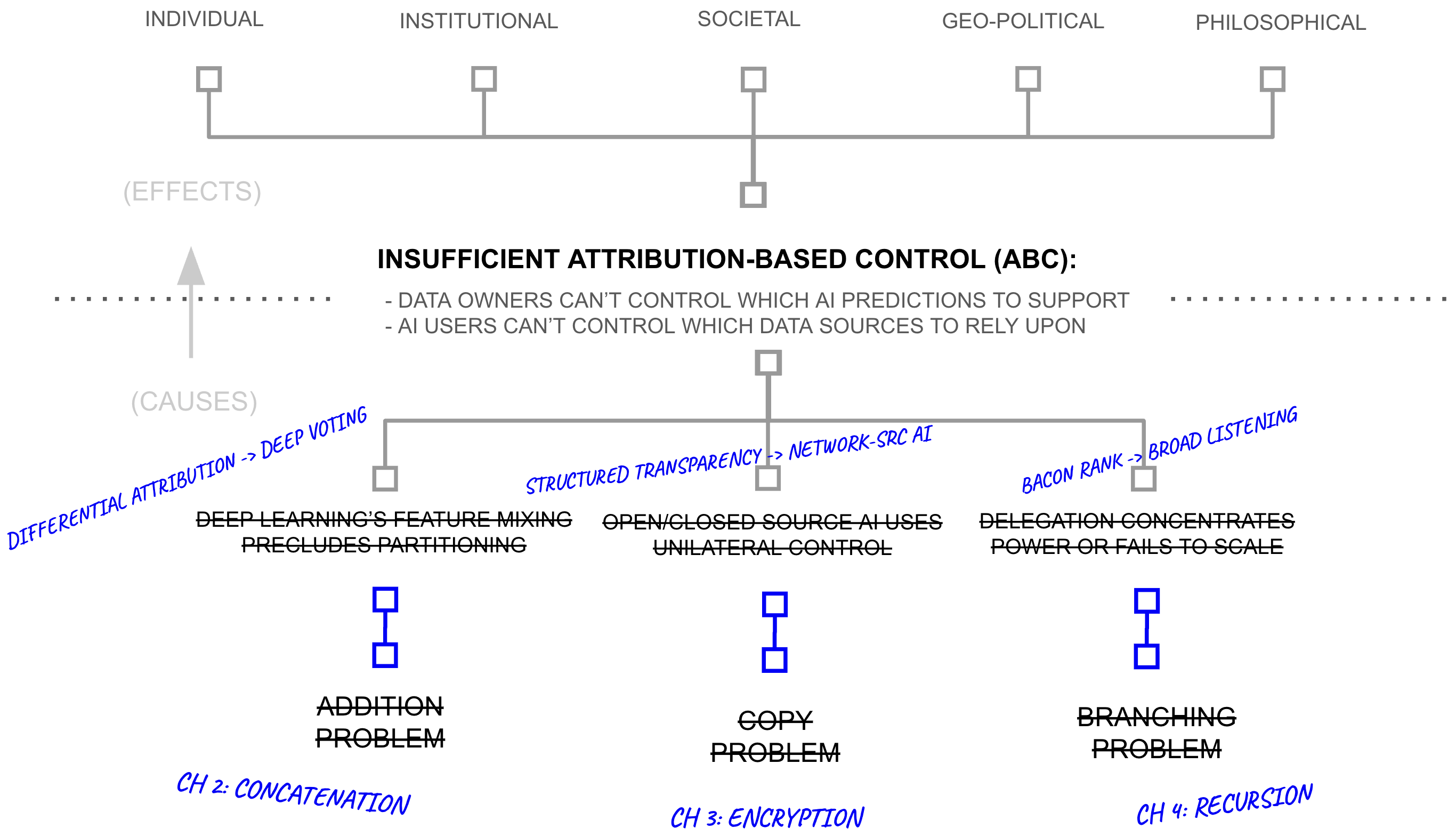
Deep voting (Chapter 2) replaces addition with concatenation in key parts of the training process, preserving source-partitioned representations so that individual contributions remain identifiable at inference time. It does this by embracing recent breakthroughs in deep learning models which partition neurons in sections, and then by re-purposing differential privacy budgeting by inverting its key term, providing differential attribution budgeting. The empirical evidence surveyed in Chapter 2 (from RETRO, ATLAS, PATE, and related systems) suggests this can achieve competitive performance while maintaining per-source attribution. But a deep voting model, like any AI model, can be copied, and whoever possesses a copy controls it unilaterally. Attribution metadata becomes advisory: the model’s owner may honor it or ignore it. Deep voting provides attribution without control.
Structured transparency (Chapter 3) addresses the control problem through a framework organised around five criteria (input privacy, output privacy, input verification, output verification, and flow governance) that can be satisfied through various combinations of cryptographic techniques. Combined with deep voting, structured transparency enables data owners to contribute to AI predictions without surrendering copies of their information, retaining cryptographic enforcement over which predictions their data supports. But structured transparency does not solve the problem of evaluating counterparties at scale: a data owner who can cryptographically control their contribution still cannot personally assess the billions of users who might request access to it. Structured transparency provides control without trust at scale.
BaconRank (Chapter 4) addresses trust through recursive propagation across low-branching networks in which each participant evaluates a small number of direct contacts within Dunbar-scale constraints. At six hops with fifty connections per node, such a network could in theory reach \(50^6 \approx 15.6\) billion sources. But BaconRank can only propagate trust assessments about sources whose contributions remain individually identifiable (requiring deep voting) and whose participation is cryptographically governed (requiring structured transparency). BaconRank provides trust propagation without anything to propagate trust about.
The three solutions are mutually dependent: each requires the other two to function as described. This mutual dependence is both the architecture’s strength (it addresses attribution, control, and trust simultaneously rather than trading one for another) and its principal vulnerability (a failure in any one component undermines the others).
Together, deep voting and structured transparency describe what Chapter 3 called network-source AI: a paradigm in which AI systems draw predictive capability from a network of data owners, each retaining control over the only copy of their information, rather than from a centralised corpus assembled through copying. BaconRank then layers on top of network-source AI to enable broad listening: network-source AI where the sources are weighted by local trust relationships between people.
Consequences Reframed
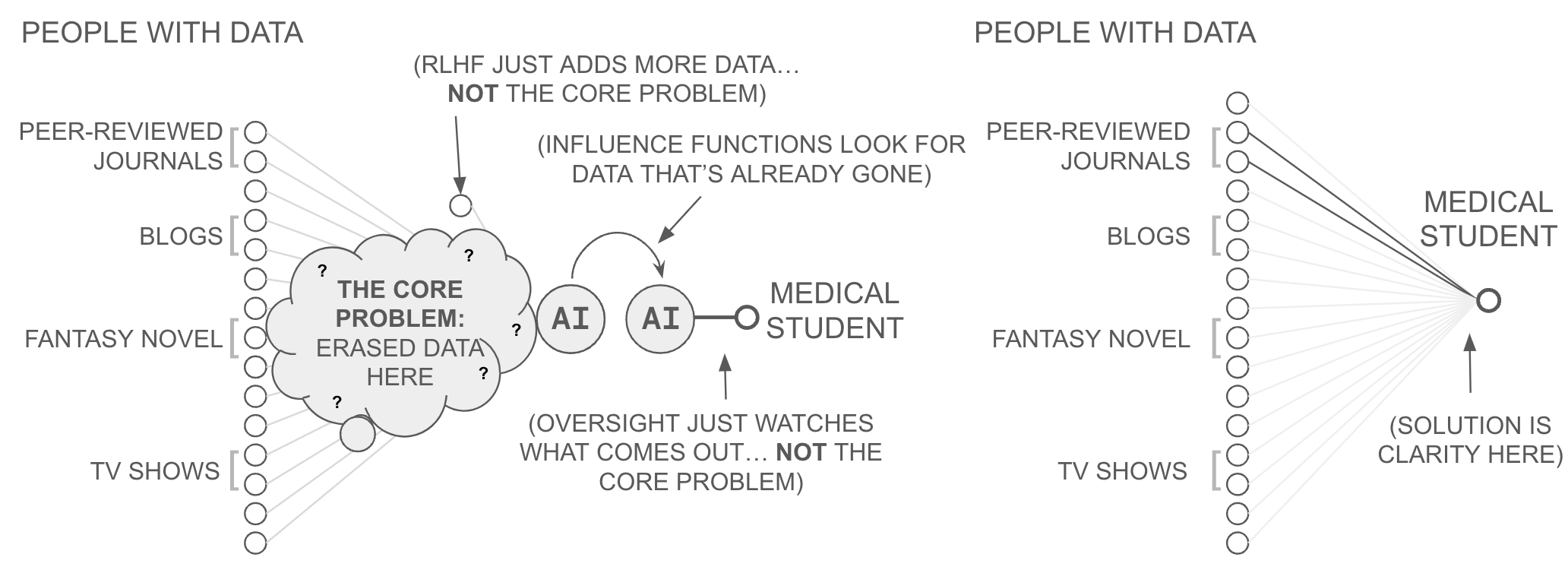
If this combined architecture scales as described, the consequences Chapter 1 traced to the absence of ABC change in character. At the individual level, the authenticity problem becomes addressable through source inspection. The medical student from Chapter 1 who queries an AI about a rare disease receives attribution metadata identifying which databases contributed and through which trust paths they were evaluated.
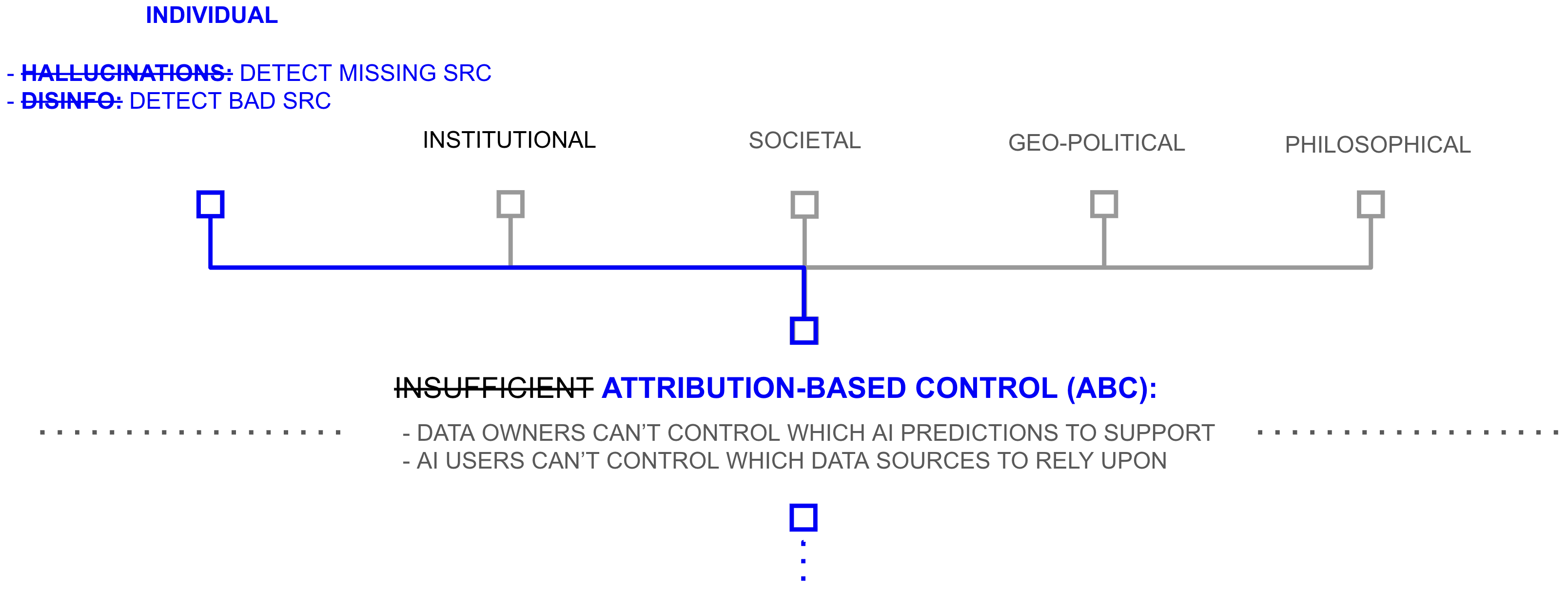
Because AI models necessarily base their outputs on some data, a hallucination manifests as the model drawing on sources that are irrelevant or insufficiently qualified for the query at hand; with attribution, this becomes visible, much as a bibliography lets a reader judge whether an academic paper’s conclusions are supported by its references. The user who can see which sources contributed to a prediction can evaluate whether those sources are qualified (the hallucination question) and whether they have been introduced in bad faith (the disinformation question). Neither hallucination nor disinformation is eliminated; the invention of the bibliography did not prevent anyone from writing anything in a book. But the mechanism for detecting both that written scholarship has relied on for centuries becomes available in the AI context as well.
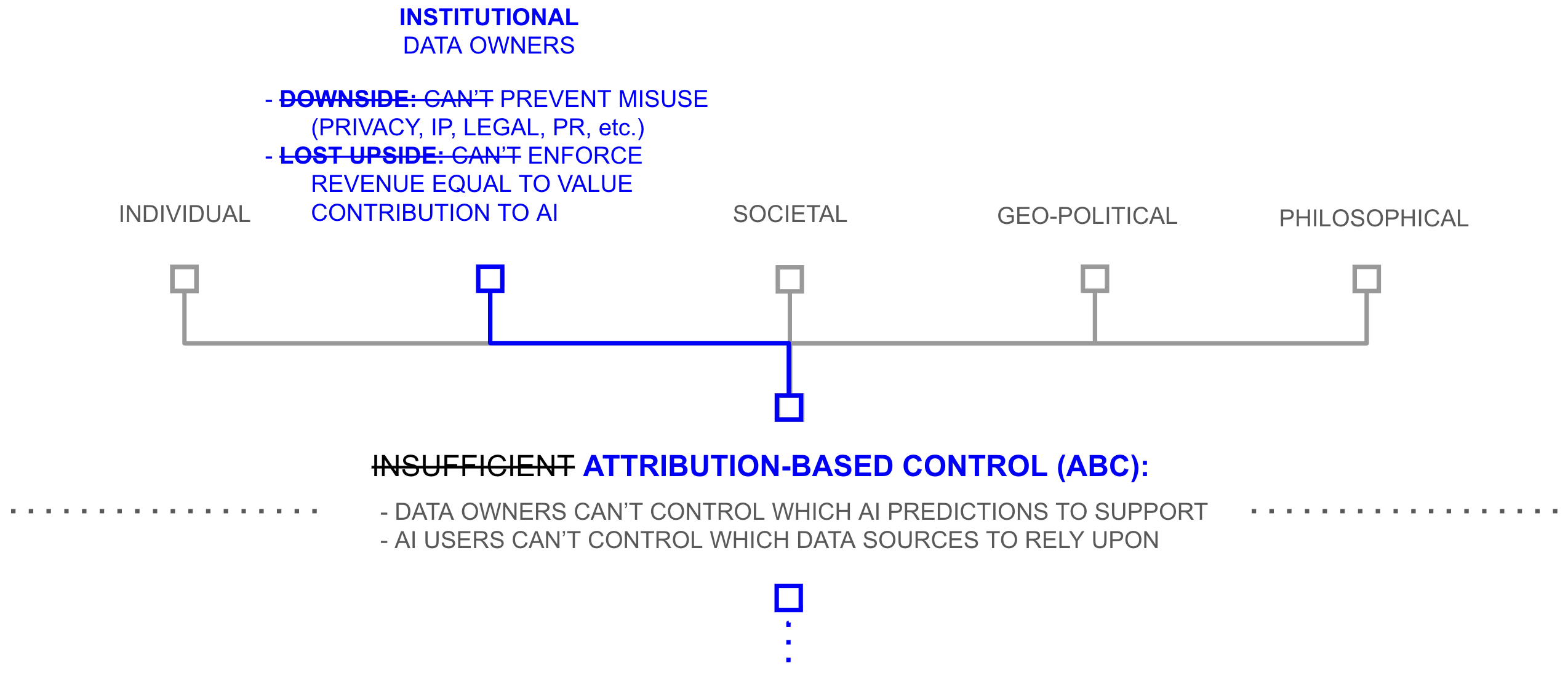
At the institutional level, the collective action failure around data sharing is addressed at the level of incentives. Under the combined architecture, a data owner considering whether to participate faces a different proposition than the current one. Instead of surrendering a copy and hoping for the best, the data owner can specify which categories of prediction their data may support, evaluate the users requesting access through trust paths they can inspect, and withdraw participation if the terms are violated. The change is structural, affecting incentives rather than merely adding technical plumbing. Chapter 2 documented that the data available for AI training represents a small fraction, perhaps six or more orders of magnitude less, than the data that exists but remains unshared, and that data is withheld because the current architecture offers no mechanism to participate without losing control. If that mechanism exists, the economic logic that drove the AI industry to repurpose graphics processors would apply with at least equal force to the vastly larger pool of data whose owners now have reason to contribute.
At the societal level, the governance problem changes. Chapter 1 argued that AI governance is currently an exercise in altruism: because AI systems are controlled by whoever holds a copy, society must hope that the institutions controlling the most powerful models will exercise that control responsibly. Chapter 1 called this the value alignment problem: AI capability and AI alignment operate independently, because scaling laws drive capability while nothing in the architecture connects that capability to the values of the people whose data produced it.
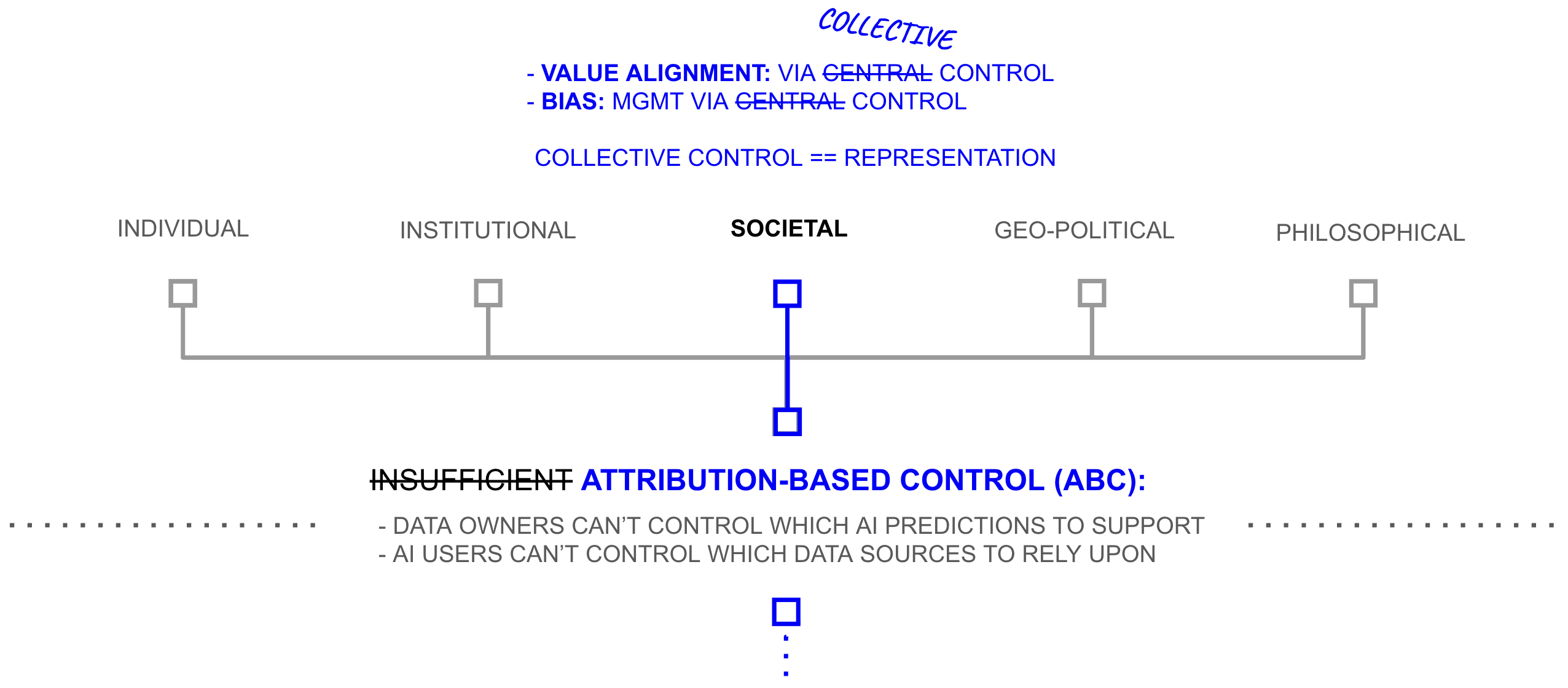
The bias problem, which Chapter 1 treated as one of AI’s most politically charged consequences, is similarly reframed. Under current architectures, bias is a training-time problem: the model absorbs whatever distributions exist in its training data, and those distributions become baked into every subsequent prediction. Under attribution-based control, bias becomes a query-time problem. Because the user can see which sources inform a prediction and can weight them through trust paths calibrated to the question at hand, the appropriate source audience can be adjusted on the fly, much as a statistician designing a survey ensures a representative sample by selecting respondents appropriate to the research question. Attribution-based control does not eliminate the political dimensions of bias, but it moves the locus of decision from a training-time choice made once by the model’s developer to a query-time choice made repeatedly by the people closest to the question.
Under attribution-based control, the value alignment problem is reframed as a problem of representative control. Data owners exercise ongoing consent over how their contributions are used. Intermediaries that fail to earn trust lose access to the data that makes them useful. The governance problem does not disappear, but its structure changes: instead of asking “will this institution behave responsibly with the power it has accumulated?” the relevant question becomes “has this institution earned the ongoing consent of the sources it depends on?”
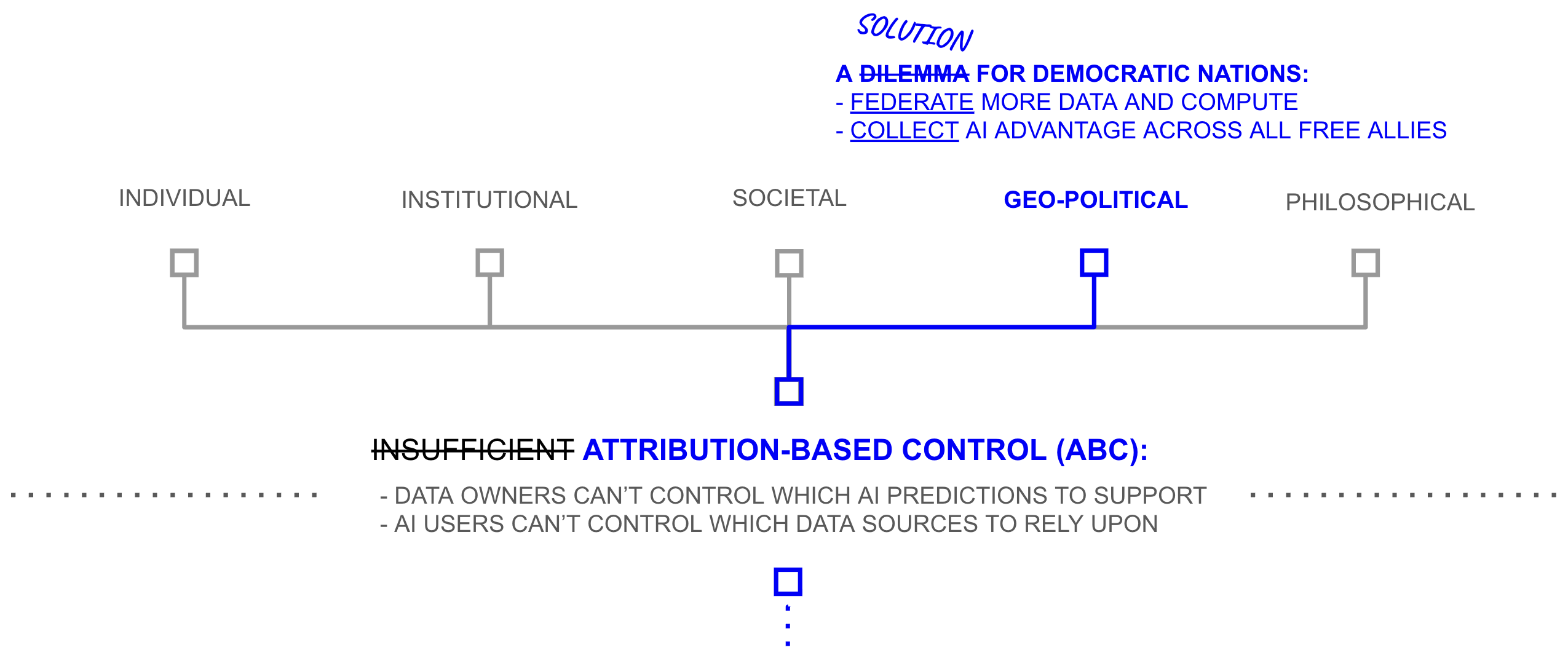
At the geopolitical level, the dilemma between democratic values and AI capability dissolves. Chapter 1 argued that AI capability is driven by scaling laws: more data and more compute yield more capable models. Under current architectures, this creates a structural dilemma for democratic nations. Centralising data and compute into a national AI programme would compromise privacy, intellectual property, freedom of choice, and the market freedoms that democracies exist to protect. But declining to centralise means ceding AI capability to authoritarian rivals who face no such constraints. Attribution-based control suggests a third path. If data owners can participate without surrendering control, AI capability can be assembled not from the resources of a single corporation or a single nation but from the collective data, compute, and talent of the global free market. A democratic coalition whose AI draws on the voluntary, revocable participation of billions of data owners across the free world would have access to a larger and more diverse data pool than any centralised programme, authoritarian or otherwise, could assemble through compulsion.
At the level of AI safety, the architecture addresses a concern that cuts across all the others. Much of the contemporary debate about AI risk centres on loss of control: the possibility that a sufficiently capable AI system, concentrated within a single institution, could pursue goals misaligned with human interests and prove difficult to constrain once it controls enough resources. Under attribution-based control, the attack surface changes. Instead of a single model whose compromise redirects the system’s capability, each prediction draws on the ongoing, revocable participation of distributed data sources, routed through trust paths that individual participants can inspect and withdraw from. Compromising such a system would require simultaneously subverting billions of independent data owners and the cryptographic infrastructure governing their participation, a qualitatively different challenge from penetrating one company’s servers. The architecture does not eliminate AI risk, but it replaces a concentrated vulnerability (one institution, one model, one point of failure) with a distributed one, and distributed systems have historically proven more resilient to both adversarial attack and internal failure than centralised alternatives.
These claims are significant, and the gap between architecture and deployment is large. But the technical path described in this thesis does offer, at the level of architecture, responses to the problems Chapter 1 raised. In a narrow technical sense, this is what the thesis set out to do, and it is sufficient. But a technical path is not the same as a built road, and the history of information technology suggests that the existence of a federated alternative has never, on its own, been enough to displace a centralised incumbent. It seems naive and farfetched to make any claim to avert the centralization of AI.