Chapter IV
From Network-Source AI to Broad Listening
Chapter Summary
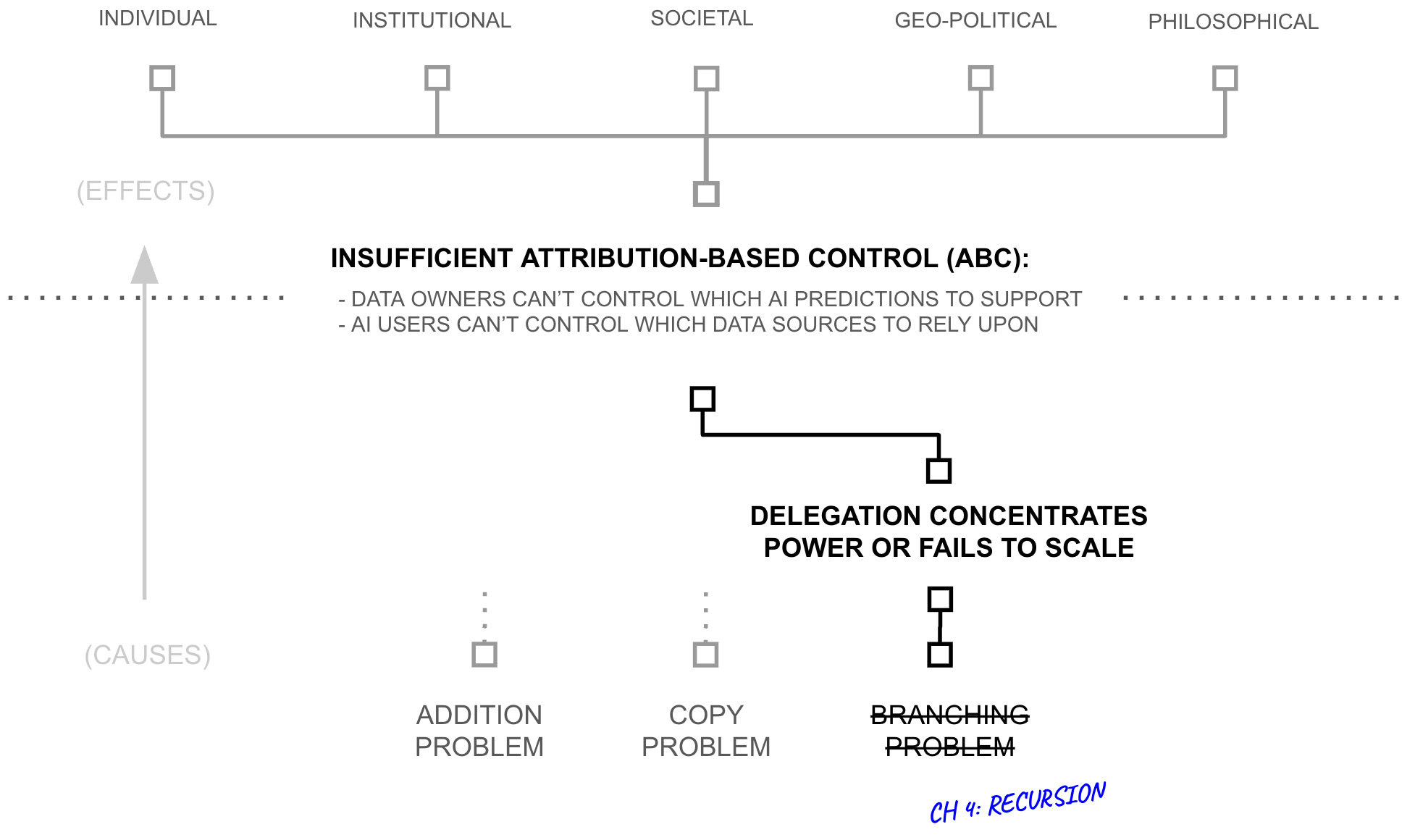
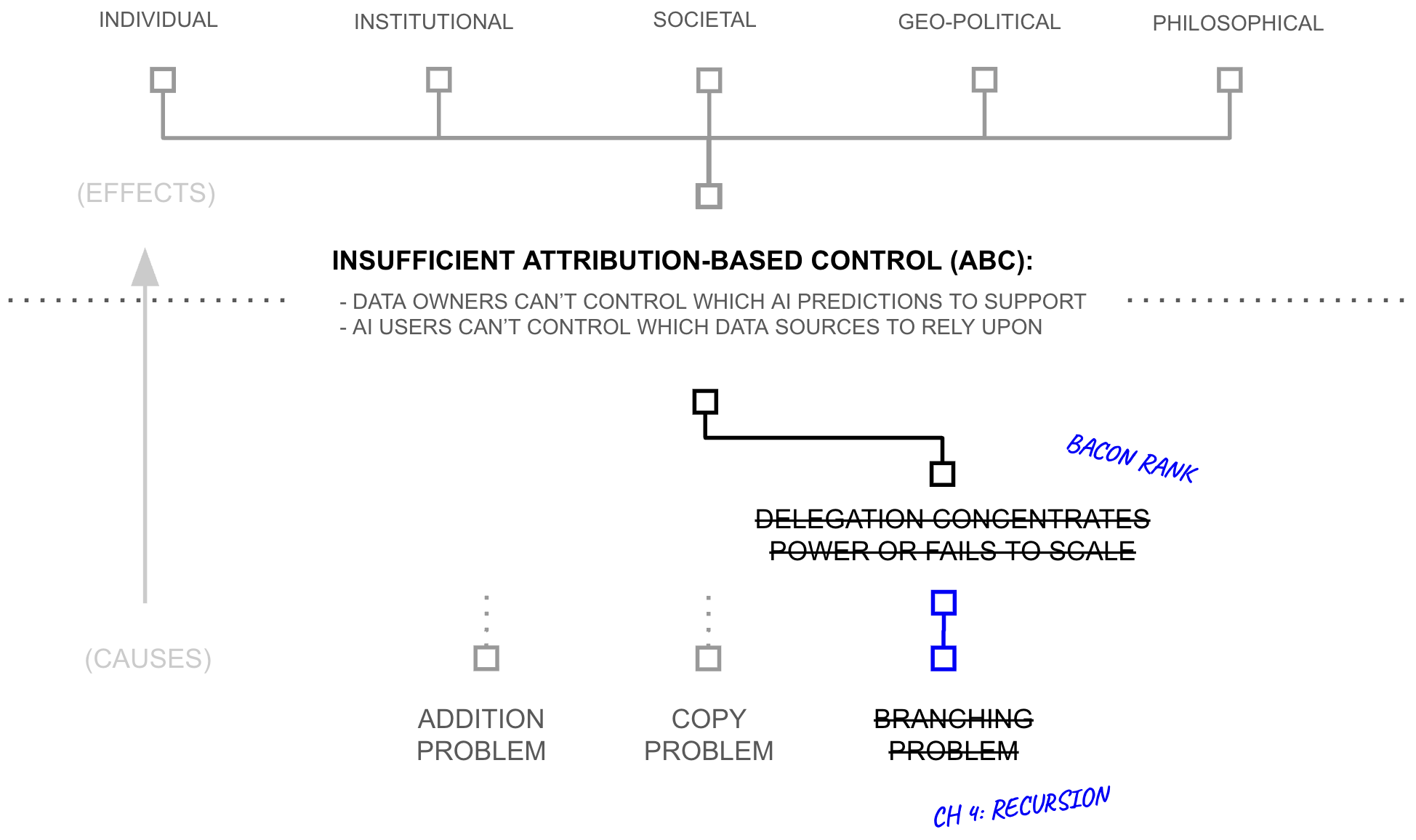
Chapters 2 and 3 developed the technical machinery to deliver ABC, but a close reading will surface that the machinery has a flaw which must be addressed: trust at scale. As individuals, AI users and data sources can evaluate perhaps 150 counter-parties by cultivating strong-tie relationships with them. Yet, owing to scaling laws, NSAI requires evaluating millions of data sources in order to curate as much data as standard AI systems. Delegation of trust evaluation is therefore necessary, but it too has a fatal flaw: if AI users and data sources delegate trust evaluation to a small collection of central parties, NSAI collapses back into the system it was meant to replace (today's centralized AI). This chapter identifies the root issue as high-branching nodes; any node connecting to millions cannot cultivate the strong-tie relationships that trust evaluation requires. The chapter then prescribes recursive delegation through low-branching networks as the remedy, yielding a new paradigm: broad listening.
The Problem of ABC in Network-source AI
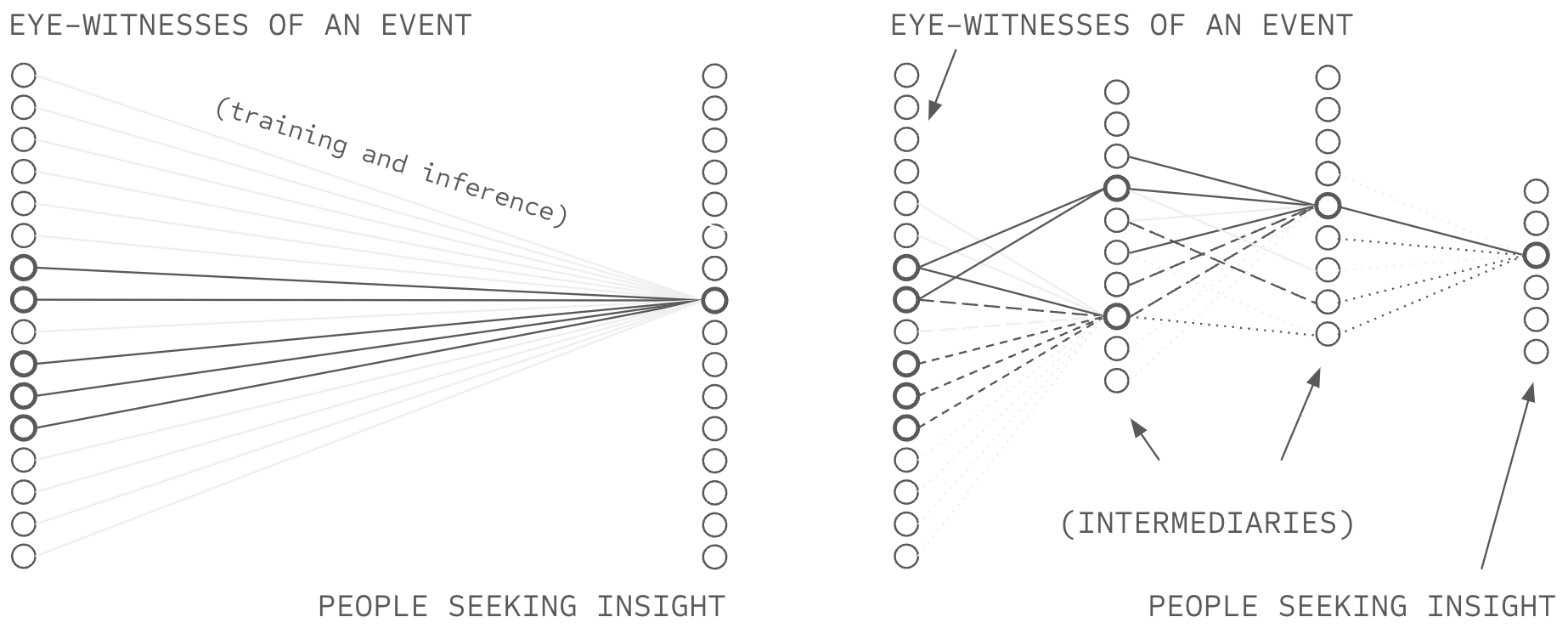
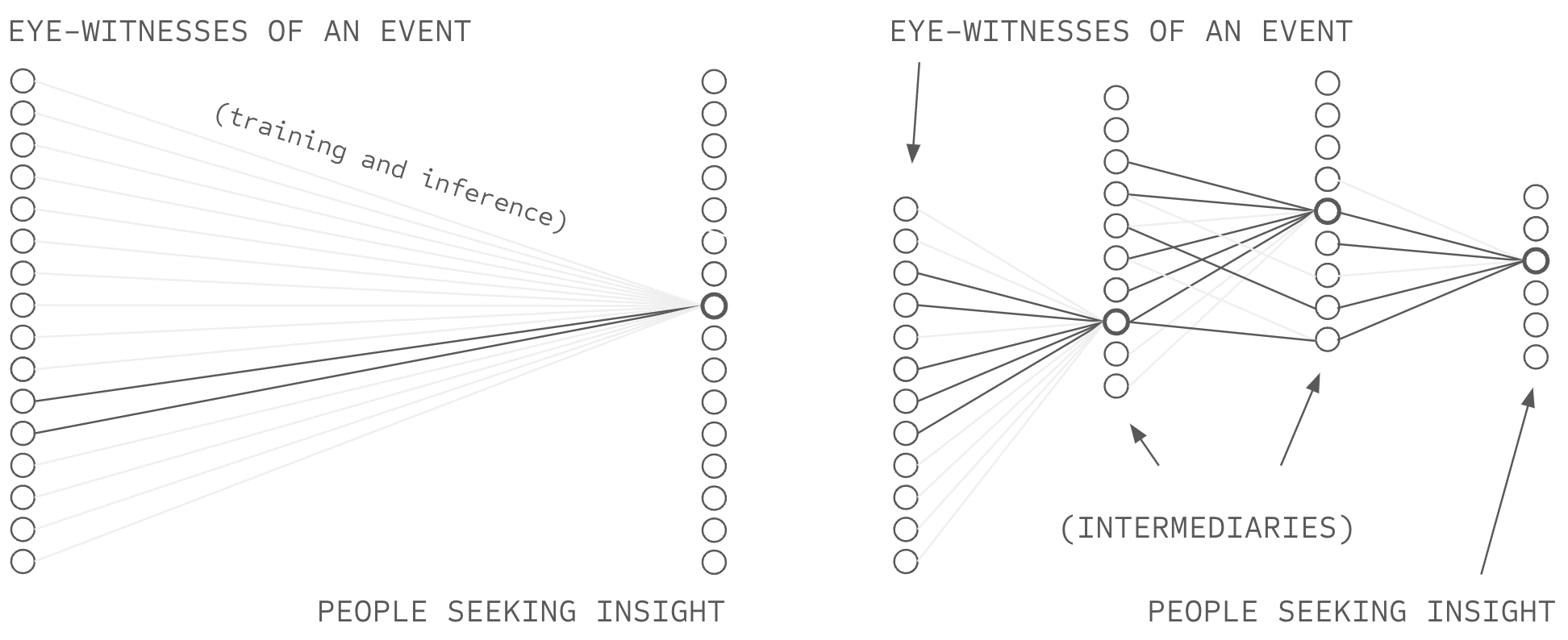
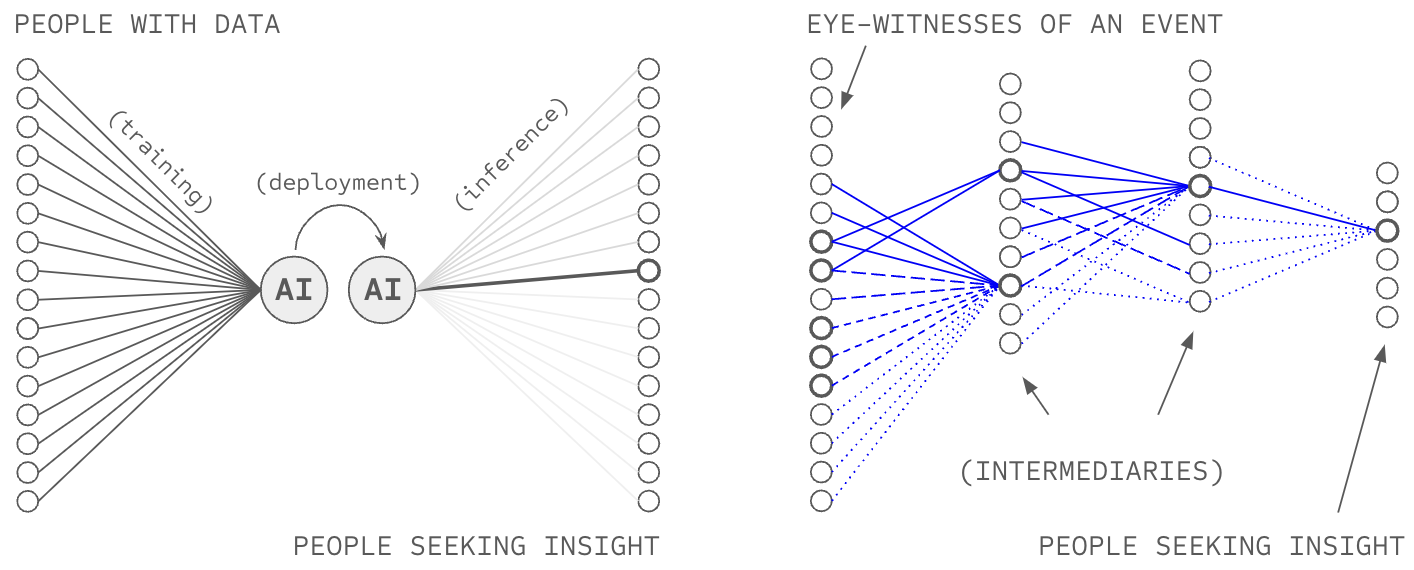
Today, a frontier AI system is trained on a curated dataset and can only leverage information obtained by the AI owning entity when making predictions. In this way, today's AI is like a rudimentary, button-less, hot-line telephone where users can only call the telephone provider for information, and the telephone provider can only reply based on information they have gathered. Network-source AI (NSAI) is like a modern telephone, giving users the ability to dial anyone in the world directly, circumventing the data collection processes and opinions of the telephone provider.1 Chapters 2 and 3 specified novel methods to make and respond to those calls: how to aggregate the responses in an attributable way (deep voting), and how to protect the calls and responses using encryption (structured transparency).
But while NSAI offers a technical capability for ABC, a subtle problem undermines it in practice: the ability to dial is not the same as knowing whom to call, and the ability to reply is not the same as knowing who to support with AI capability. Deep voting aggregates contributions according to trust weights (the intelligence budget), and structured transparency protects those weights, but neither chapter specifies where the weights come from (the machinery operates on weights; it does not produce them). The system is incomplete in precisely the way a combustion engine is incomplete without fuel: the machinery is specified, but the input that makes it run is not. This matters because the weights are not incidental to attribution-based control, they are the means of controlling attribution. Without the ability to reliably form trust weights, deep voting might as well be vanilla deep learning and NSAI might as well be today's frontier AI systems. Without this final ingredient, the telephone can dial anywhere, but the user does not know whom to call. This chapter addresses that gap.
1 Related: the difference between circuit switched and packet routing telephone networks
The Diagnosis
Let's say you receive a problematic medical test and need an oncologist to follow up. Using your phone, you can theoretically dial any oncologist on earth, but your phone's contacts contains zero oncologists whose judgment you have personally evaluated. Let's say your city has hundreds of oncologists, your country has tens of thousands, and in theory you could contact them one by one (by looking them up online). Each would probably answer, but each answer would contain what the oncologist chooses to share, something like "yes I'm a great doctor... what is your insurance and when can you come in for an evaluation?"
In a way... the oncologist is not really who you want to call. You want to call the patients, people who trusted each oncologist with their life and learned whether that trust was warranted. The patients have information beyond what the typical oncologist is likely to disclose, such as whether the doctor listens, whether they rush, whether their diagnoses prove correct, and whether their patients are cured.
However, you cannot collectively dial all the patients of the world's oncologists; even if you had a team of people to help you make thousands of phone calls, you do not know the names or numbers of each oncologist's patients. They are not listed anywhere you can find. Some of them are almost certainly friends of friends of friends of yours... so the path to an introduction might exist... but you cannot see or traverse it. Indeed, the information is almost certainly there. But you have no way to ask.
First Why: Why Individuals Cannot Evaluate at Scale
Trust requires observation. If no one has ever observed a party perform, no one can trust that party to perform well; one can only hope. One might be tempted to argue that everyday life involves trusting many people one has not directly observed (e.g., taxi drivers, baristas) because they are credentialed in some way. But credentials, ratings, and recommendations do not create trust; they transfer it. Even someone's location implies membership in a community, that they have successfully avoided being arrested or otherwise removed from that part of society. Geography is its own kind of credential, transferring trust from your community to you. At the origin of every trust chain, someone watched.
Consider the CV of the oncologist from the example above. It represents layers of transferred trust from medical schools that observed her learn, residency programs that observed her practice, and credentialing boards that reviewed her record. Patients who trust the CV are trusting these institutions to have done the observation on their behalf. But after treatment, successful patients hold something stronger: trust built through their own time with her, perhaps through diagnoses that proved correct or through her listening when they were afraid. While the CV offers borrowed trust, the relationship offers earned trust. And crucially, the relationship is mutual. Because the oncologist depends on her patients for referrals and reputation, if she misleads her patients, she loses something she values. This mutual dependency helps to make the trust enforceable.
Sociologists call these high-trust relationships "strong ties": relationships characterized by sustained interaction, emotional investment, and mutual obligation (Granovetter 1973). The last element is crucial. Mutual obligation means both parties have stakes in the relationship's continuation... and therefore both bear costs if they betray it. This is what makes strong-tie trust enforceable rather than merely hopeful.
The problem is that building strong-tie relationships requires attention, and attention is finite. Dunbar's research establishes the constraint as universal across humans: approximately 150 stable relationships... a limit traced to neocortex size itself (Dunbar 1993).
Meanwhile, NSAI requires trust assessments for millions of sources. If competitive AI systems require data at thirty-trillion-token scale from millions of sources (see Chapter 2), and individuals can maintain at most 150 strong ties, the gap spans 4+ orders of magnitude. That gap will not close through individual effort, and delegation is therefore necessary. The question is whether delegated trust can preserve what makes strong ties work: the observation, sustained interaction, emotional investment, and mutual obligation that makes accountability possible.
Second Why: Delegation Centralizes or Fails to Scale
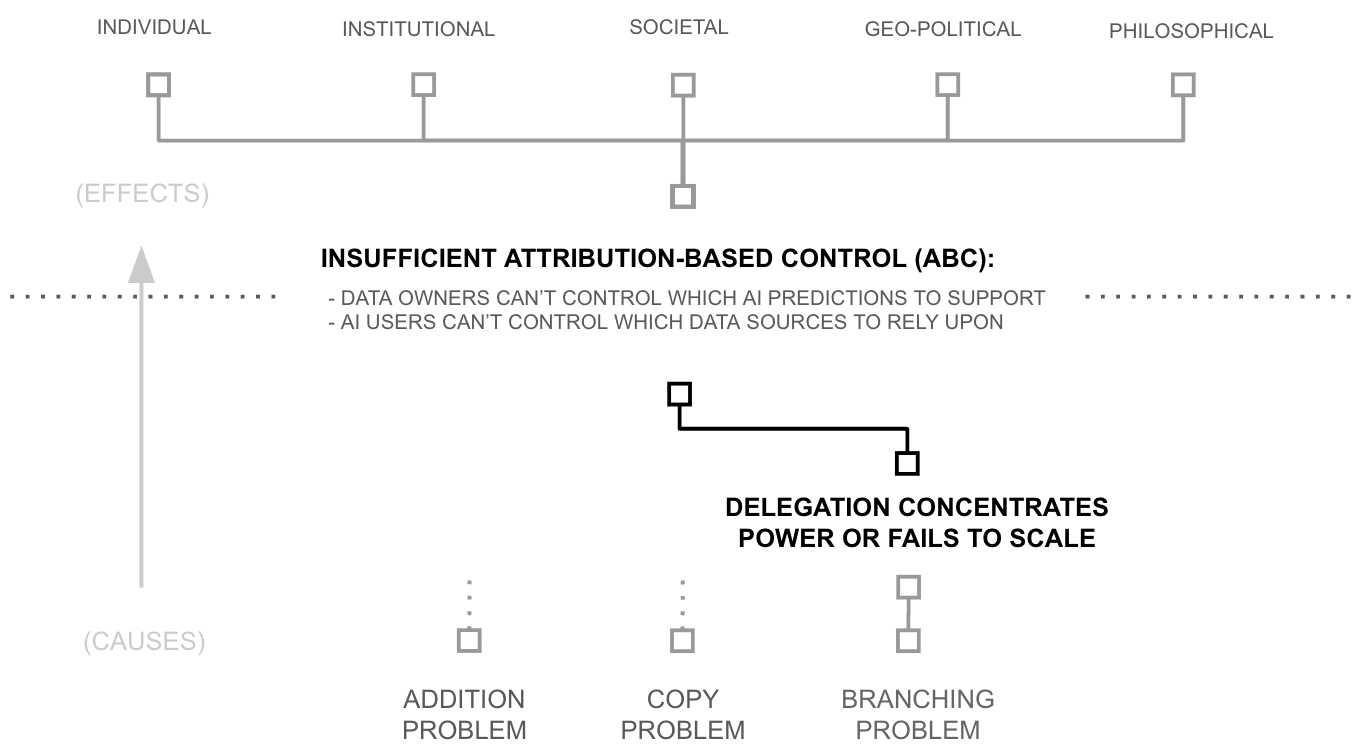
Two paths exist: delegate through individuals, or delegate through groups of individuals organized as institutions. One might propose a third path, delegate to technology (to algorithms), but this merely relocates the question; trusting an algorithm means trusting whoever built it and deployed it. The choice reduces to individuals or institutions. The question for each path is whether it preserves the mutual observation and stakes that make strong-tie trust enforceable.
The Institutional Path
The institutional path appears elegant: delegate trust evaluation to AI platforms, let them aggregate signals from billions of sources (e.g., curate training data, RLHF data). But this recreates the architecture NSAI was designed to escape. If users delegate trust evaluation to Google or OpenAI, those institutions decide which sources are trustworthy. Control has not been distributed; it has been relocated. Central institutions cannot deliver ABC by definition.
This argument is sufficient, but let us more closely inspect the mechanics of trust centralization. After all, ABC is not an end in itself. Chapter 1 introduced ABC as a means to address concrete problems such as: privacy erosion, copyright disputes, data siloing, concentration of power, and competitive disadvantage against centralized adversaries. Even if we abandoned the goal of ABC, these problems (and the stakeholders who care about them) would not disappear. They would continue to obstruct institutional paths to trust evaluation at scale.
Consider data owners. As Chapter 2 documented, 6+ orders of magnitude of data remains siloed because data owners do not trust institutional intermediaries with their information (Grybauskas 2023; O'Brien 2025; Grynbaum and Mac 2023; Youssef et al., 2023). This resistance is rational. Data owners are each one of millions; the institution has no particular stake in protecting any single owner's interests. Without mutual stakes, data owners have no mechanism to hold institutions accountable, only the hope that the institution will behave well (often in the face of evidence they will not, e.g. privacy and copyright violations).
Consider governments. The company Klout processed forty-five billion social interactions daily to score 750 million users (Rao et al., 2015), attracted $200 million in acquisition value, and served over two thousand business partners (Fortune 2014). Western society shut it down anyway... the day GDPR took effect (Oremus 2018). Privacy regulation made Klout's level of trust evaluation illegal by making its level of surveillance illegal. Yet, GDPR is not a local legislation targeted a specific companies like Klout, it is a European wide paradigm shift in privacy expectations, inspiring a wave of similar legislation around the world (Simmons 2022).
Or consider accountability generally within western society. General trust evaluation at scale requires significant surveillance and likely a significant power imbalance between the surveil-er and surveilled. Yet, democratic values prohibit comprehensive surveillance. There is no policy that satisfies both constraints, or a widely deployed technology that circumvents them. Caught between these imperatives, western societies pay the costs of both while achieving the full benefits of neither.
The result is visible in current online infrastructure. A handful of social media platforms observe and manage approximately 8.5% of all waking human experience on earth... four trillion hours annually (Hootsuite 2024).2 This is surveillance at civilizational scale, yet the online trust verification problem remains woefully unsolved: half of web traffic is bots (Imperva 2024), up to 30% of online reviews remain fraudulent (D'Onfro 2013; Cross 2022), and state actors operate troll factories at scale (Foreign, Commonwealth & Development Office 2022). Western platforms cannot even reliably verify that people online are human, let alone whether they are trustworthy sources of information on specific topics.
Centralization in the Western context fails because surveillance is limited and because of the power imbalance between user and platform. An institution serving billions need not depend on any single user, and a user who is one of billions cannot hold the institution accountable (except through some similarly powerful institution... which itself then has an analogous accountability relationship). And in response to the power imbalance, users are both wary of platform interests, and governments taking steps to curtial platform power (e.g., privacy and copyright law).
According to the theory, centralization cannot deliver attribution-based control; it relocates control rather than distributing it. And in practice, centralization triggers exactly the resistance that blocks comprehensive trust evaluation: data owners withhold information from intermediaries they cannot hold accountable, and governments resist the surveillance and power imbalance such intermediaries would require. Taken together, the institutional path to trust verification at scale is closed.
2 Calculated as 4 trillion hours divided by approximately 47 trillion global waking hours (8 billion people × 16 hours/day × 365 days).
The Individual Path
The alternative is delegation through individuals: trust your friends and colleagues to evaluate sources on your behalf. This preserves what institutions cannot offer: strong-ties. Your friend has 150 relationships, not millions; you are one of 150, not one of millions; and your friend depends on your continued relationship for support, reciprocity, and reputation within your shared community. If your friend misleads you, they lose something they value. The mutual stakes that make trust enforceable remain intact.
But individual delegation cannot directly reach the scale that competitive AI platforms require. The Dunbar limit applies to delegated relationships as surely as direct ones. If each friend evaluates within their limit of 150, and you have 150 friends, your network reaches at most 22,500 sources (assuming no mutual friends among them), at best 2+ orders of magnitude short of the millions of sources that competitive AI systems require.
Taken together, institutions fail because they struggle to secure a public mandate for sufficient surveillance, and because they cannot sustain mutual stakes at scale. Individuals preserve mutual stakes but cannot reach AI-level scale. Both paths appear closed, but notice that the failures now share a common structure: somewhere in the path, the ratio of connections (scale) to accountability (surveillance and mutual stakes) breaks down. Let us consider this more closely.
Third Why (Root Cause): The Branching Problem
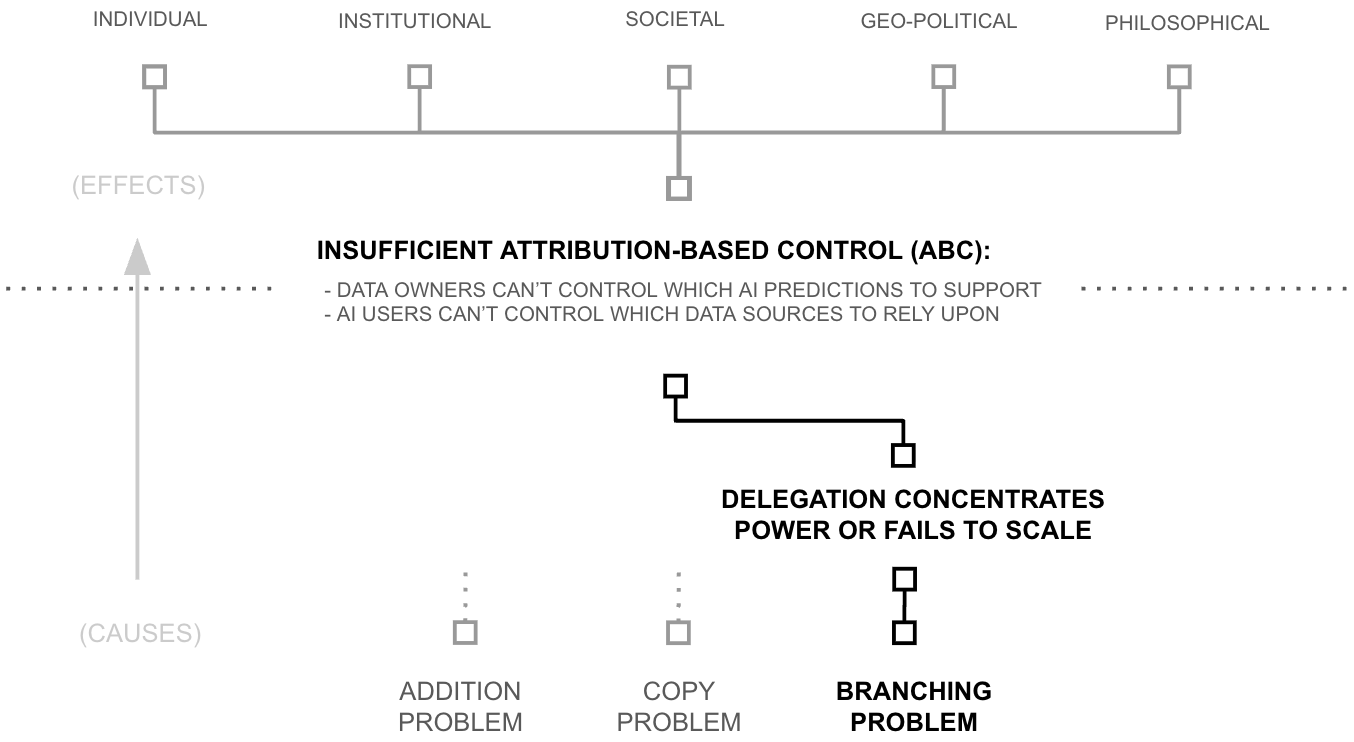
Consider what happens when nodes of vastly different cardinality connect, pictured in Figure 4.5. One institution sits in the middle, billions of sources connect on one side, billions of users on the other. Now ask: what stake does each party have in the relationship? The institution has two billion connections; if it loses one, it loses one two-billionth of its network. But a user has perhaps 150 relationships, constrained by the same cognitive limits that necessitated delegation in the first place. If the institution is one of their few trusted intermediaries for a particular topic (e.g. oncologist ratings), it may represent a significant fraction of their access to information.
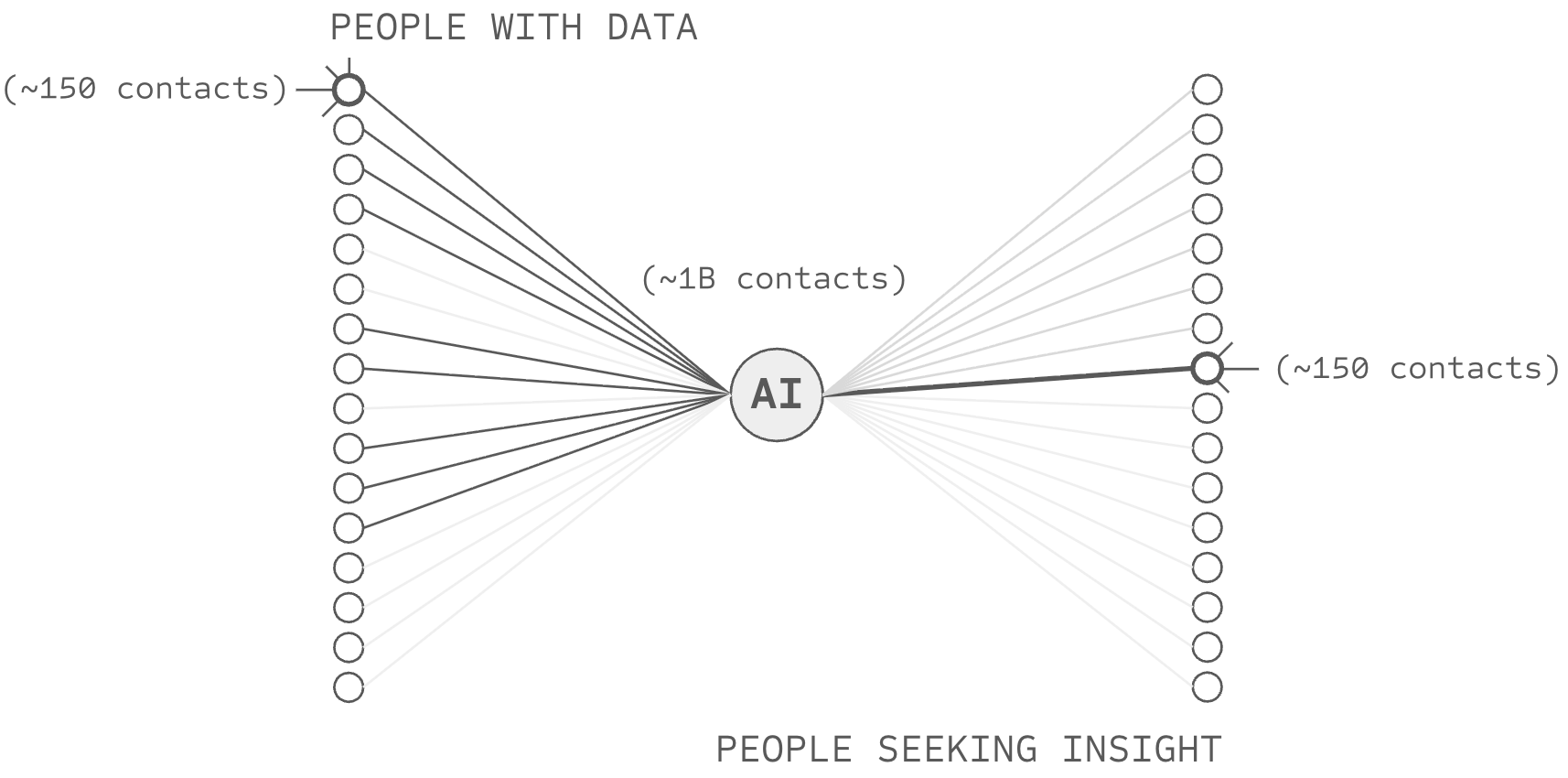
The stakes are asymmetric. The institution can betray counterparties at negligible cost; their departure costs it nothing it would notice. Mutual stakes require that both parties in each relationship lose something meaningful if the relationship fails. When one side of an edge has two billion connections and the other side has 150, the asymmetry is structural, and accountability cannot survive it.
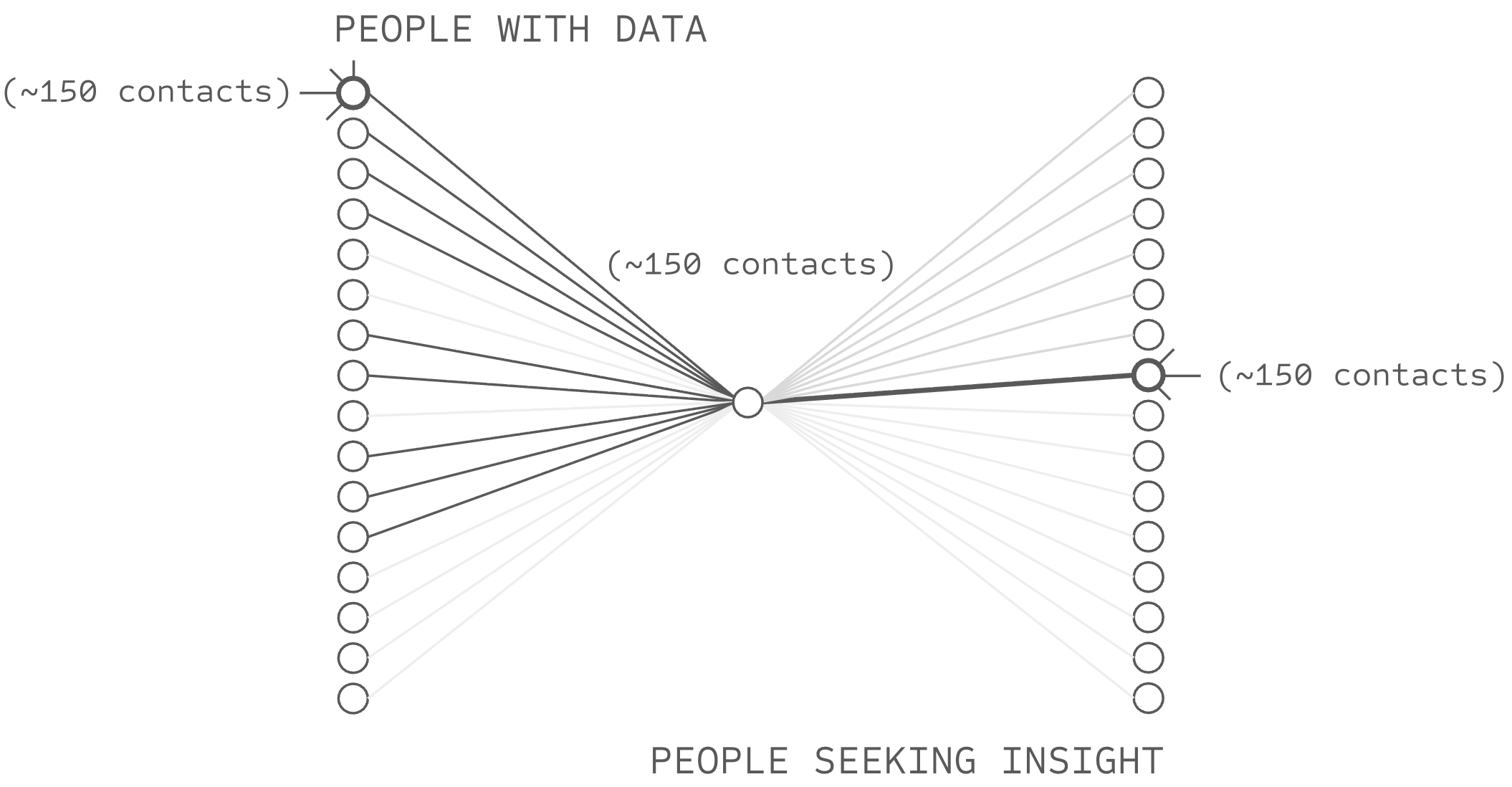
Now consider what happens when nodes operate at comparable scale, pictured in Figure 4.6. If you connect to 150 friends, and each friend connects to 150 sources, you reach 22,500 sources—far short of the million-source scale competitive systems require. To reach a million through only two hops, your 150 friends would each need roughly 7,000 connections. But a friend with 7,000 connections recreates the asymmetry problem: you are one of 7,000, your stake in the relationship is unchanged, but their stake in you has diluted significantly. The accountability that made your friendship trustworthy does not survive the transition. Alternatively, if instead your friends each connected to only a handful of sources (perhaps 10), reach would shrink further, dependency would concentrate on those few connections, and the network would fail to achieve competitive scale. The failure mode is not merely "too many connections" but deviation from Dunbar-scale in either direction.
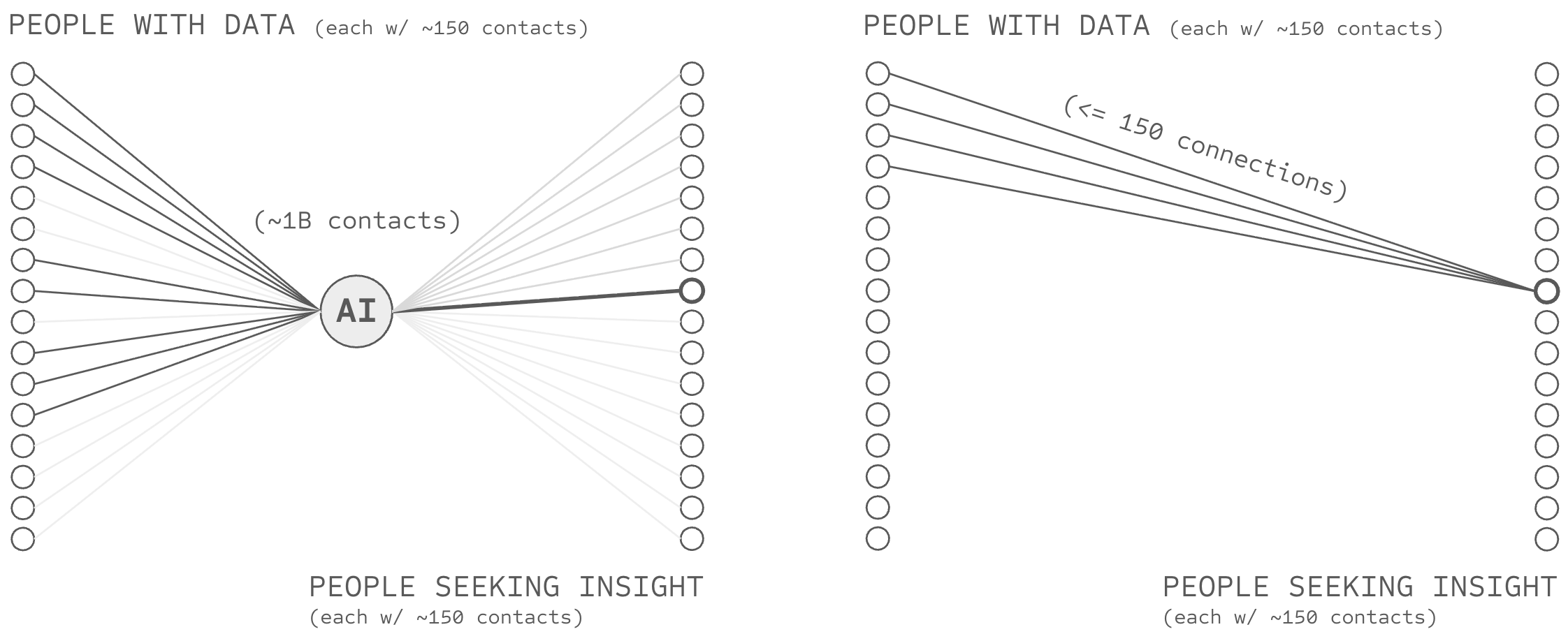
This is the root beneath both failures. The institutional path fails because institutions operate far above Dunbar scale while their users cannot... billions of connections on one side, hundreds on the other, creating asymmetric stakes that subvert accountability. The individual path fails because short paths to competitive scale require someone in the chain to exceed Dunbar limits, recreating the same imbalance one hop away. Both are instances of the same architectural constraint: any path to scale that includes a node deviating from their peers' scale (e.g., Dunbar-scale), connected to nodes that do not. This activates the responses... weaker parties that hide data, and governments that pass laws which protect the weaker from the stronger, introducing friction to coordination in the process (i.e., privacy laws hindering verification ability). This problem cascades to sustain long-term pressures against free society (i.e. privacy, autonomy, personal property, etc.) and exposure to fraud and deception (i.e. fake accounts, gaming of metrics, etc.). But these problems rest on a crucial central root: the branching problem.
The Branching Problem
Trust struggles to traverse nodes with highly unbalanced numbers of relationships, with Dunbar's scale acting as a central empirical reference point. As nodes operate higher than Dunbar scale ($k \gg 150$) their ability to sustain strong-tie relationships with others diminishes. As nodes operate below Dunbar scale ($k \ll 150$) they underutilise capacity and concentrate their dependency on their counterparties. Imbalance between connected nodes ($k_1 \gg k_2$) creates asymmetric stakes that undermine accountability, and Dunbar's number is a hinge point; trust degrades as nodes deviate from Dunbar-scale cardinality.
Contemporary AI systems exhibit extreme deviation from Dunbar-scale at both ends of their architecture: at training time, one model connects to billions of sources; at inference time, one model connects to billions of users. Both points constitute nodes operating orders of magnitude above relational capacity. Network-source AI, as specified in Chapters 2 and 3, does not escape this constraint. Deep voting requires trust weights, and structured transparency protects those weights, but neither specifies how weights are formed. If users delegate weight-formation to platforms operating at billion-scale, the branching problem reappears at the delegation point, and NSAI inherits exactly the accountability failures it was designed to escape.
The Branching Puzzle
Competitive AI systems require trust paths to billions of sources, yet the branching problem suggests that nodes struggle to connect with more than ~150 people (i.e. Dunbar's number) if they are to propagate trust. Short paths to billions require high-branching nodes; high-branching nodes undermine trust. The branching puzzle: how can trust delegation reach global scale when trust degrades as nodes deviate from Dunbar-scale cardinality?
This is where the analysis arrives. Chapters 2 and 3 specified how to build AI systems that preserve attribution through aggregation and protect control through transparency. But neither chapter addressed where trust weights come from. Without a solution to the branching puzzle, users must either delegate weight-formation to high-branching platforms (undermining attribution-based control and inheriting the accountability failures that motivated NSAI) or accept limited reach. The next section explores a solution.
The Oncologist and the Branching Puzzle
A patient receives a troubling test result and needs an oncologist. Two paths exist.
The platform path. The patient consults a review platform with two billion users and tens of thousands of oncologist reviews. The platform's algorithm surfaces a five-star physician. The patient books an appointment, receives treatment, and dies eighteen months later from a cancer that a competent oncologist would have caught. The review was fake... posted by a marketing firm working for the oncologist and undetected by the platform. The patient is dead, but what does the platform lose? One two-billionth of its user base. The loss is invisible to the platform; the accountability is virtually nonexistent. The platform continues operating, its revenue unaffected and algorithm unchanged. This is the high-branching failure: billions of connections on one side, hundreds on the other, and no mechanism for consequences to flow.
The friend path. The patient asks their 150 friends whether anyone knows a good oncologist. No one does—oncology is specialised, and the patient's immediate network lacks relevant experience. The patient asks friends to ask their friends: 150 times 150 yields 22,500 people, still no oncologist referral with direct experience. The information exists somewhere in the social fabric, but three hops away, four hops away, beyond the reach of the patient's strong-tie network. The patient gives up and returns to the platform. This is the low-branching failure: Dunbar-limited connections at every node, and no path long enough to reach relevant sources.
Both paths fail. One has reach without accountability. The other has accountability without reach. The branching puzzle: is there a third path that offers both?
Third Hypothesis: Reach via Recursion
In theory, a third path exists: recursion. If each node in a social graph maintains $k$ connections and trust propagates through chains of depth $H$, theoretical reach scales as $O(k^H)$. Fifty connections across six hops has the theoretical potential to reach fifteen billion sources:
$$\text{Reach} = k^H = 50^6 = 15{,}625{,}000{,}000$$
This is mathematical possibility, not a claim about actual social networks, but the pattern has precedent. Information propagation phenomena like word of mouth have operated this way for thousands of years; as they advanced prior to mass broadcasting technologies, the spread of early fire-making, agriculture, and religious ideas all propagated through peer networks of this kind. Academic citation networks, PageRank, and Wikipedia exhibit similar structure: researchers cite dozens of sources, pages/papers link to dozens of others, people/editors assess within their capacity at each hop in the graph, and no central node determines outcomes (Lawrence et al., 1999; Page et al., 1999; Reagle 2010).
Yet communication infrastructure has upgraded these mechanisms unevenly. The printing press, radio, television, and digital networks each scaled broadcasting to larger audiences while leaving the capacity to filter, synthesize, and verify information at human speed (Goldhaber 1997). The branching problem is a consequence of this asymmetry: when broadcasting scales but trust does not, bottlenecks form, and power concentrates. Scaling the capacity to listen as broadly as we already broadcast is what this thesis calls broad listening.
The Requirement
The mathematics above establish that reach without branching is possible in theory. Three questions remain before this possibility becomes useful: are social graphs connected enough to facilitate global communication using this recursive technique, does trust survive recursive depth, and can coordination costs be reduced enough such that this form of global communication infrastructure can compete with centralized, high-branching platforms?
Regarding whether social graphs are connected enough, a long-standing meme has suggested that each person in the world is separated by six degrees of separation, a claim a team of Facebook researchers later reduced to four degrees of separation (Backstrom et al. 2012). It would seem that the world's social graph is connected enough for four hops to facilitate information propagating globally. Regarding the remaining two questions, the Second Hypothesis and First Hypothesis sections below address them respectively.
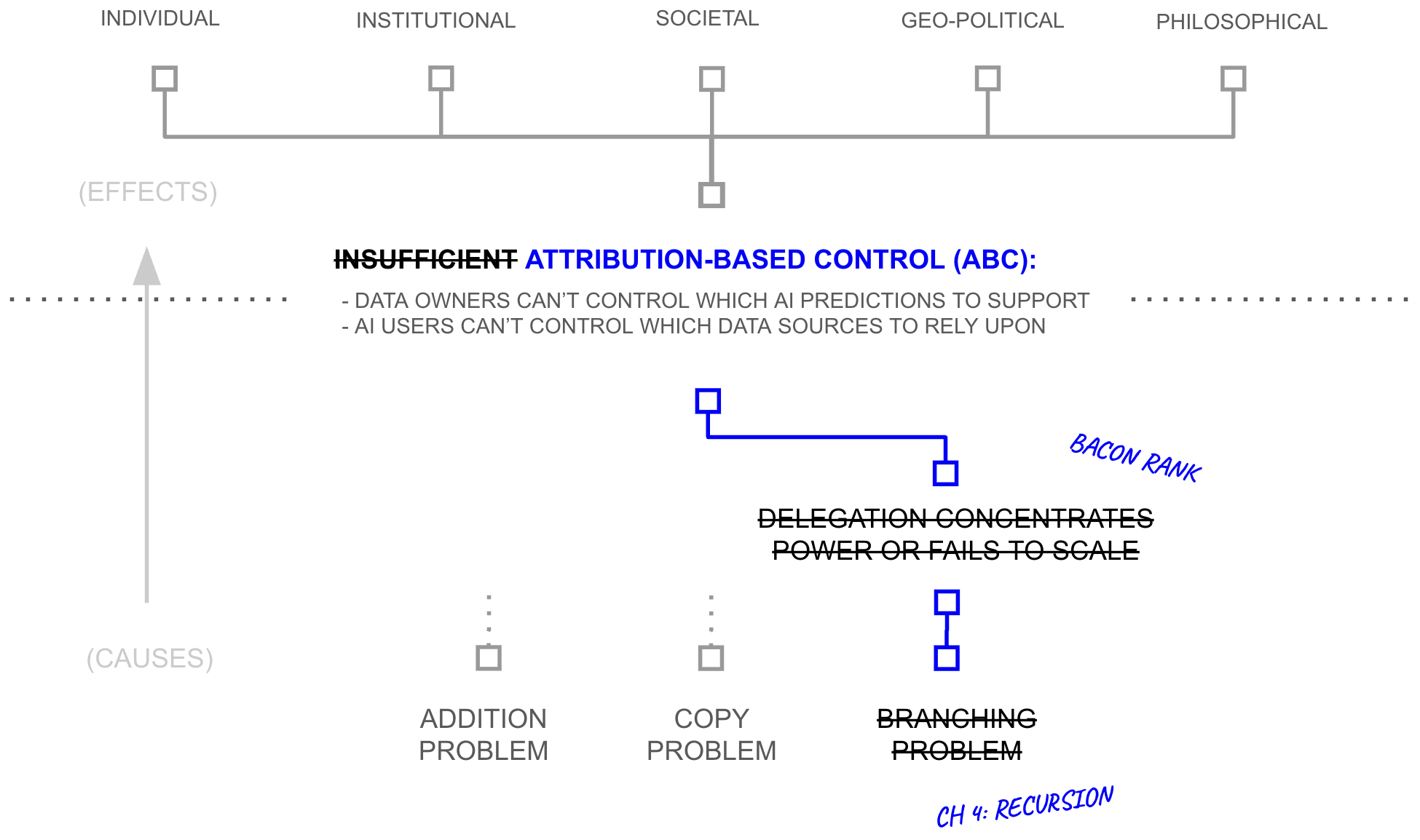
Second Hypothesis: Delegation Without Concentration
The Third Hypothesis established that recursive networks can theoretically reach 15.6 billion sources through six hops of fifty connections each, but reach is not the same as trust. Everyone knows the telephone game: a message degrades with each retelling, and by the end of a chain of a dozen or so people a message arrives as noise. If trust propagation works the same way, then recursive reach is just recursive degradation, and billions of unreliable paths are uninteresting.
Yet, the telephone game fails for a specific reason, which is that it has a single serial path, one chain of retelling with one point of failure at every hop. Thus, a single liar or a single misremembering anywhere in the chain corrupts the entire message irreversibly. But this degradation isn't inherent to recursion itself; it's a property of recursion without redundancy.
BaconRank: Trust Propagation Through Redundant Paths
This chapter proposes a trust propagation algorithm called BaconRank, named after the "six degrees of Kevin Bacon" game that illustrates the small-world property of social networks. BaconRank is inspired by Google's PageRank algorithm (Page et al., 1999), which demonstrated that recursive propagation through a link graph could produce meaningful authority scores at web scale. Both algorithms share a core insight: the importance of a node can be inferred from the structure of paths leading to it, without any centralized authority assigning scores. However, BaconRank differs from PageRank in three ways that reflect the shift from ranking web pages to propagating interpersonal trust:
- Query-relative. PageRank computes a single global ranking: every user sees the same authority scores. BaconRank computes a personalized ranking that originates from a specific querying user and propagates outward through their trust relationships. Two users with different social graphs will assign different trust scores to the same source. This is analogous to Personalized PageRank (Haveliwala 2002), but grounded in social trust rather than topic similarity.
- Domain-specific. PageRank assigns a single authority score per page. BaconRank maintains separate trust weights per domain of expertise (e.g., medical knowledge, financial analysis, climate science), so that a participant trusted for medical insight need not be trusted for financial advice.
- Probabilistic aggregation. PageRank distributes a node's authority equally across outgoing links and sums incoming contributions (with normalization). BaconRank aggregates incoming trust via a probabilistic OR, which treats each incoming path as an independent confirmation. This ensures that trust scores remain bounded in $[0,1]$ without requiring global normalization, and that redundant paths increase confidence with diminishing returns rather than unbounded accumulation.
We now define BaconRank formally.
BaconRank
Let $G = (N, E)$ be a directed trust graph where $N$ is the set of all participants and $E$ is the set of directed edges between them, with each edge representing a direct trust relationship. Let $d$ denote a specific domain of expertise over which trust is evaluated. Each participant $u \in N$ maintains a trust weight $w_{u,v}^d \in [0,1]$ for each direct contact $v \in \text{contacts}(u)$, representing $u$'s assessment of $v$'s reliability in domain $d$. Let $q \in N$ be the querying user who initiates the trust propagation. Let $h \in \{0, 1, \ldots, H\}$ denote the current hop, where $h = 0$ is the origin and $H$ is the maximum propagation depth (e.g., $H = 6$). Let $T_h(n) \in [0,1]$ denote the cumulative trust that has reached participant $n \in N$ after $h$ hops of propagation, with initial condition $T_0(q) = 1$ and $T_0(n) = 0$ for all $n \neq q$. BaconRank proceeds in two alternating steps at each hop:
Map. Each participant $n$ who has received trust $T_h(n) > 0$ distributes it to their direct contacts, weighted by their trust assessments:
$$\text{Map}_n(T_h(n)) = \{(v,\; T_h(n) \cdot w_{n,v}^d) : v \in \text{contacts}(n)\}$$
That is, each contact $v$ of participant $n$ receives a share of $n$'s trust, scaled by how much $n$ trusts $v$ in domain $d$.
Reduce. Each recipient $m \in N$ may receive trust from multiple senders at hop $h$. Let $n_1, n_2, \ldots, n_k$ be the $k$ participants who forward trust to $m$. These contributions are aggregated via probabilistic OR:
$$T_{h+1}(m) = 1 - \prod_{i=1}^{k}(1 - T_h(n_i) \cdot w_{n_i,m}^d)$$
Each additional path can only increase $T_{h+1}(m)$, but with diminishing returns: the product term shrinks toward zero as $k$ grows, so $T_{h+1}(m)$ approaches but never exceeds $1$. After $H$ hops, the final trust score $T_H(s)$ for each source $s \in N$ represents the querying user $q$'s transitive, domain-specific trust in $s$, aggregated across all paths of length at most $H$.
The Map–Reduce structure reflects an architectural property wherein each participant executes only local operations (weighting their own contacts) without access to the global graph. This means BaconRank can be implemented in a distributed setting where no single party observes the full network topology, a property that aligns with the structured transparency guarantees of Chapter 3.
This property was first introduced in Chapter 1, which identified the breadth criterion: truth-finding requires aggregating from many independent sources because coordinated deception becomes logistically harder when information must be consistent across many independently weighted witnesses. If the graph provides thousands of redundant paths to a single source (a number that depends on network structure and connectivity), then a deceiver at any hop would need to corrupt many chains simultaneously and consistently, whereas the telephone game requires corrupting only one. As redundant paths increase, the probability that any single corrupt path dominates the aggregate approaches zero, confirming the intuition that a mesh of thousands of independent paths is categorically more robust than a single wire.
One caveat, stated plainly: redundancy handles independent failures and uncoordinated deception, but it doesn't handle coordinated attacks where adversaries control many nodes along many paths at once. How much path diversity real social networks actually provide, and how far network structure constrains adversarial coordination in practice, are questions which are out of scope for this thesis. What this architecture changes is the economics of deception: corrupting this system requires corrupting many independent paths rather than a single intermediary.
Why Centralization Was a Symptom, Not a Goal
Even if trust survives depth, a concern remains: information technology tends to centralize. The Second Why documented the pattern in detail: delegation systems tend to centralize under competitive pressure or fail at useful scale. Email was once a distributed system of peer connections and a handful of platforms now operate it; web search began with multiple competing companies using decentralized ranking algorithms and consolidated under a dominant platform. If history is any guide, this system may face strong centralizing pressures too.
Yet, these systems didn't necessarily centralize because centralization is the natural state of information systems. They centralized for many well known reasons (network effects, economies of scale, user convenience, etc.), but perhaps these reasons are underpinned by three more fundamental driving forces of centralization.
The first is information overload. When there's more information than any person can process, the job of synthesis and indexing gets handed to an intermediary (search engines, news editors, recommendation algorithms, etc.), and those intermediaries centralize because they can filter the flood more efficiently than individuals acting alone. Deep voting (Chapter 2) addresses this cause specifically: source-partitioned representations can compress and index information without any central party needing to hold all the data.
Privacy is the second. Information too sensitive to share directly gets handed to institutions people hope will keep it safe: banks, hospitals, intelligence agencies, etc. These institutions centralize because centralization solves a real problem: some information can't flow freely between individuals. Structured transparency (Chapter 3) replaces the need for a trusted custodian with cryptographic protocols that let participants share information without surrendering copies of it.
The third cause is harder to see because it's the water we swim in: veracity. When information might not be true, people defer to institutional arbiters (journalists, researchers, rating agencies) who centralize because someone has to adjudicate what counts as real. BaconRank (this chapter) offers an alternative through recursive trust propagation, enabling truth-finding through redundant paths without any central authority.
Three causes of centralization, and three chapters that each built a tool for one of them. The delegation systems that centralized (academic citations, web search) faced some or all of these limitations, which were then amplified by other centralizing forces like network effects. This architecture faces the same competitive pressures, but it meets them with specific technical remedies targeted at each underlying cause.
Broad listening is what emerges when information overload, privacy, and veracity are all addressed simultaneously through decentralized means. Centralization was never the goal of delegation systems; it was in part a symptom of missing technical infrastructure, and the theoretical frameworks for that infrastructure now exist. And whether decentralized alternatives will outcompete centralized incumbents in practice is genuinely unknown. But the structural necessity has changed: for centuries, addressing information overload, privacy, or veracity at scale strongly favoured centralized approaches. The technical landscape has changed, even if the competitive and social landscape remains to be tested.
First Hypothesis: Broad Listening Competes
Broad listening removes the structural necessity for centralization, but architectural possibility doesn't imply practical competitiveness. Even if the architecture is sound, might it take forever to run? At present, typing a question into a frontier AI system returns an answer in seconds, whereas broad listening proposes a system where a query propagates through six hops of a social graph, with human attention (perhaps even human approval) required at every node. Recursive consultation through social networks has always been slow. Asking a friend to ask a friend to ask a friend takes days or weeks, because each person in the chain has to notice the message, think about it, write a reply, and pass it along.
But the slowness of recursive consultation has never been a property of the network's reach; it's a consequence of the human coordination cost at each node. Deep voting proposed to dramatically reduce this bottleneck by separating weight specification from query-time coordination. Participants record their trust assessments in advance (who they trust, for which domains, how much), and when a query arrives, the system propagates trust according to these weights without requiring any human being to check their phone.
The propagation computation requires $O(k \cdot H)$ operations per participant, which with $k \approx 50$ contacts and $H \approx 6$ hops amounts to roughly 300 operations regardless of how large the network grows. The synthesis step requires language model inference, which currently takes seconds. The relevant comparison here is between days of sequential human phone calls and seconds of parallelised matrix multiplication.
The Honesty Problem
Yet, speed becomes irrelevant if participants can't provide honest assessments, and recording trust assessments in a digital system creates vulnerabilities that face-to-face word of mouth doesn't have. If assessments are observable, employers can identify which employees distrust company sources, governments can identify which citizens trust opposition voices, and commercial actors can map relationships for targeted manipulation. Facing those risks, rational participants would either refuse to participate or provide strategically dishonest assessments, and either outcome renders BaconRank useless regardless of its other architectural properties.
Structured transparency is designed for exactly this problem, providing something analogous to end-to-end encryption for the trust propagation process. Assessments travel over encrypted data so that predictions don't reveal who assessed whom; computations can be verified without exposing the underlying inputs; and cryptographic keys are distributed across participants so that no single party can observe the full process or override it unilaterally.
The result is that participants can record honest assessments without exposing themselves, though whether they actually will is a question about human behaviour rather than technology, and one this thesis can't answer. What has changed is that the principal technical barrier has been addressed: before structured transparency, honest participation in a global trust network required trusting every intermediary with the content of one's assessments. The cryptographic tools to remove that requirement now exist, even if practical deployment at scale introduces additional engineering challenges.
Other Practical Concerns
The reader might also suggest other practical concerns. Will a popular product for broad listening be open source? Will it rely upon proprietary services which recentralize control (e.g. Google's Play Store and Android)? Might open source implementations and public infrastructure receive enough funding to compete with the entrenched interests of trillion dollar companies which rely upon the attention economy for vast sums of revenue? These are all crucial questions which should be explored. This thesis describes a practical possibility, as well as some incentive reasons why this approach could out-compete existing approaches (e.g. incentives discussed in the Introduction chapter, data siloing challenges with centralized infrastructure discussed in Chapter 2, etc.), but the world is complex and further investigation is required.
The Gap Closes
Nevertheless, the First Why identified a gap between what individuals can evaluate (approximately 150 relationships, constrained by Dunbar's number) and what competitive AI systems require, which is trust assessments for roughly a billion sources. Seven orders of magnitude separate the two.
To address this challenge, a combination of mechanisms, each built independently for a different problem, compose into a system that addresses this trust gap. Recursive depth gives the network its reach (six hops of fifty connections spanning fifteen billion sources), and the redundancy of thousands of independent paths scatters uncoordinated deception against the aggregate. But reach and integrity mean nothing if the process takes weeks, which is where deep voting changes the calculation: pre-recorded weights replace sequential human coordination with seconds of parallelised matrix operations. The remaining vulnerability is that participants might lie about their weights if they fear exposure, which is what structured transparency addresses through encryption that doesn't require trusting any intermediary. And BaconRank ties it together, converting trust-weighted aggregation across these redundant, encrypted, computationally efficient paths into verified information without a central arbiter.
None of this is new as a pattern: recursive trust propagation is how human societies have always worked, and people have always asked friends of friends for advice. What's new is the identification of specific barriers that prevented this ancient pattern from scaling (coordination cost, privacy risk, and veracity uncertainty) and the demonstration that technologies which already exist, combined through the architecture described in this thesis, can address each one. The result is something like word-of-mouth upgraded to operate at machine speed, global scale, and with cryptographic protection. Whether this composition can actually compete with the platforms people use today is a question this thesis can't settle, but the technical coherence of the composition (the fact that the pieces fit) is what this thesis has argued.
Conclusion: Broad Listening
What does it actually look like to participate in this system? From the perspective of a data source, it means maintaining a local LLM (e.g. ClaudeBot) as an interface to the world, a piece of a deep voting architecture that encodes your knowledge and answers queries on your behalf. A doctor can't personally field a billion queries about oncology, but a trained LLM maintained on infrastructure the doctor controls, encrypted through structured transparency and governed by intelligence budgets the doctor sets, can respond to verified queries automatically. This isn't a "digital twin" in the popular sense; it's the doctor's voice in the system, operating within bounds she chose and contributing to a collective intelligence she helps govern.
From the perspective of a user, a query propagates through the network in milliseconds. BaconRank identifies thousands of relevant sources, weighted by trust accumulated through recursive paths, and their partitions get synthesised through encrypted computation. What comes back isn't anonymous per se, as it arrives with attribution metadata about the people and trust paths used to produce the AI result. But that attribution metadata also doesn't need to divulge the exact identities of the parties who contributed, merely the attestation that they were sourced through a verified chain of trust, and corroborated with some level of redundancy. A medical claim can be traced to oncologists trusted by patients who recovered, or flagged as originating from sources with no verifiable track record. But the exact names of each participant are not strictly speaking necessary, and if trust needs adjusting, the user can adjust their intelligence budget and query again, refining the prompt with each iteration.
The observation that most people miss is that when anyone uses a modern AI chat system, they're already talking with the world in a way analogous to the form described above. The training data came from the world, the fine-tuning reflected human preferences, and the predictions synthesise patterns drawn from billions of people. What's absent is any control over that connection: which part of the world you're talking with, whether what you hear is genuine, and whether the conversation is being observed. In a very real sense, the interface already exists within major AI products like ChatGPT, Claude, and Gemini. What doesn't exist is the user's ability to control it... with attribution-based control.
The Telephone
Before the rotary dial was introduced in 1919, a telephone caller picked up the receiver and spoke with an operator, a centralized intermediary who decided whom to connect, leaving the caller with no control over the connection. After the telephone dial was introduced, a telephone caller chose their contacts directly. And once phones became digital, and contained contact lists, a telephone caller could pull up trusted numbers without memorizing them. After end-to-end encryption, the conversation became private on apps like Signal and WhatsApp. The telephone itself didn't change through any of these transitions; what changed was the caller's relationship to it, from passive recipient of a centralized service to active participant in an end-to-end encrypted network.
AI is at the operator stage of this transformation. A user queries a frontier system and receives a response assembled from data they didn't choose, governed by values they didn't set, built on reasoning they can't trace. The user picks up the receiver (chatgpt.com) and gets whoever the operator (OpenAI) connects them to, with no ability to dial, no contact list of trusted sources, and no way to verify that the line is private or that the voice on the other end is telling the truth. The model decides who the user talks to within the inner workings of its neurons. Even when a model queries a web source or local context window, its still the neurons which (in a hidden way) decide what information to use to create predictions... and nobody can decode the inner workings of those neurons to know which sources are truly being relied upon.
In short, the AI user has no buttons, and attribution-based control provides them. Deep voting is the dial: source-partitioned representations let a user choose which sources inform each prediction, the way a caller selects a number. Structured transparency is the encryption: cryptographic protocols that protect the channel without requiring anyone to trust a central custodian. BaconRank is the contact list: a trust-weighted directory of the whole world, discovered through recursive networks of verified relationships, letting a user find trustworthy sources many hops away without ever leaving Dunbar scale.
The AI model is the telephone. The AI model has always been a kind of telephone for listening to large groups of people. What's been missing are the buttons, the contact list, and the encryption to protect it. Broad listening is what happens when these get added, when people use AI not to receive intelligence from a central source but to communicate, at scale, through trust-weighted channels, with cryptographic guarantees, with the world.
References
- (1973). The Strength of Weak Ties. American Journal of Sociology, 78(6), 1360–1380.
- (1993). Coevolution of neocortical size, group size and language in humans. Behavioral and Brain Sciences, 16(4), 681–735.
- (2023). Will Twitter's new rate limits really stop scraping? Built In, July.
- (2025). Reddit sues AI company Perplexity and others for 'industrial-scale' scraping of user comments. Associated Press, October.
- (2023). The Times sues OpenAI and Microsoft over A.I. use of copyrighted work. The New York Times, December.
- (2023). Organizational factors in clinical data sharing for artificial intelligence in health care. JAMA Network Open, 6:e2348422.
- (2015). Klout score: Measuring influence across multiple social networks. Proceedings of the IEEE International Conference on Big Data, 2282–2289.
- (2014). Klout acquired for $200 million by Lithium Technologies. Fortune, March.
- (2018). Klout is dead, just in time for Europe's GDPR privacy law. That's not a coincidence. Slate, May.
- (2022). 17 countries with GDPR-like data privacy laws. January.
- (2024). Digital 2024: Global Overview Report. Hootsuite & We Are Social.
- (2024). 2024 Bad Bot Report. Imperva Threat Research. Reported via Forbes, April 2024.
- (2013). A whopping 20% of Yelp reviews are fake. September.
- (2022). Up to 30% of online reviews are fake and most consumers can't tell the difference. November.
- (2022). UK exposes sick Russian troll factory plaguing social media with Kremlin propaganda. UK Government Press Release, May.
- (1999). Digital libraries and autonomous citation indexing. Computer, 32(6):67–71.
- (1999). The PageRank citation ranking: Bringing order to the web. Technical report, Stanford InfoLab.
- (2010). Good faith collaboration: The culture of Wikipedia. MIT Press.
- (1997). The Attention Economy and the Net. First Monday, 2(4).
- (2012). Four Degrees of Separation. ACM Web Science 2012, 33–42.
- (2002). Topic-sensitive PageRank. Proceedings of the 11th International Conference on World Wide Web, 517–526.